Nomograms in Stata


|
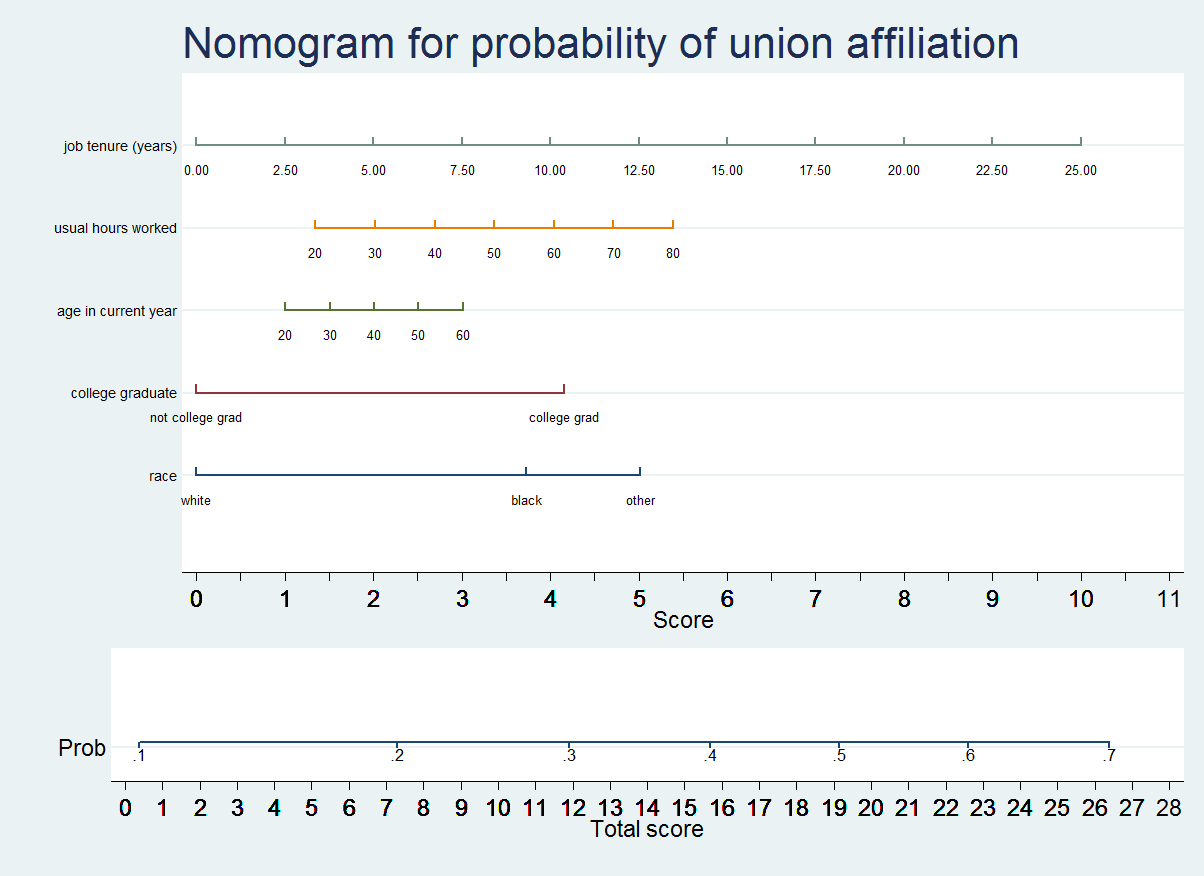
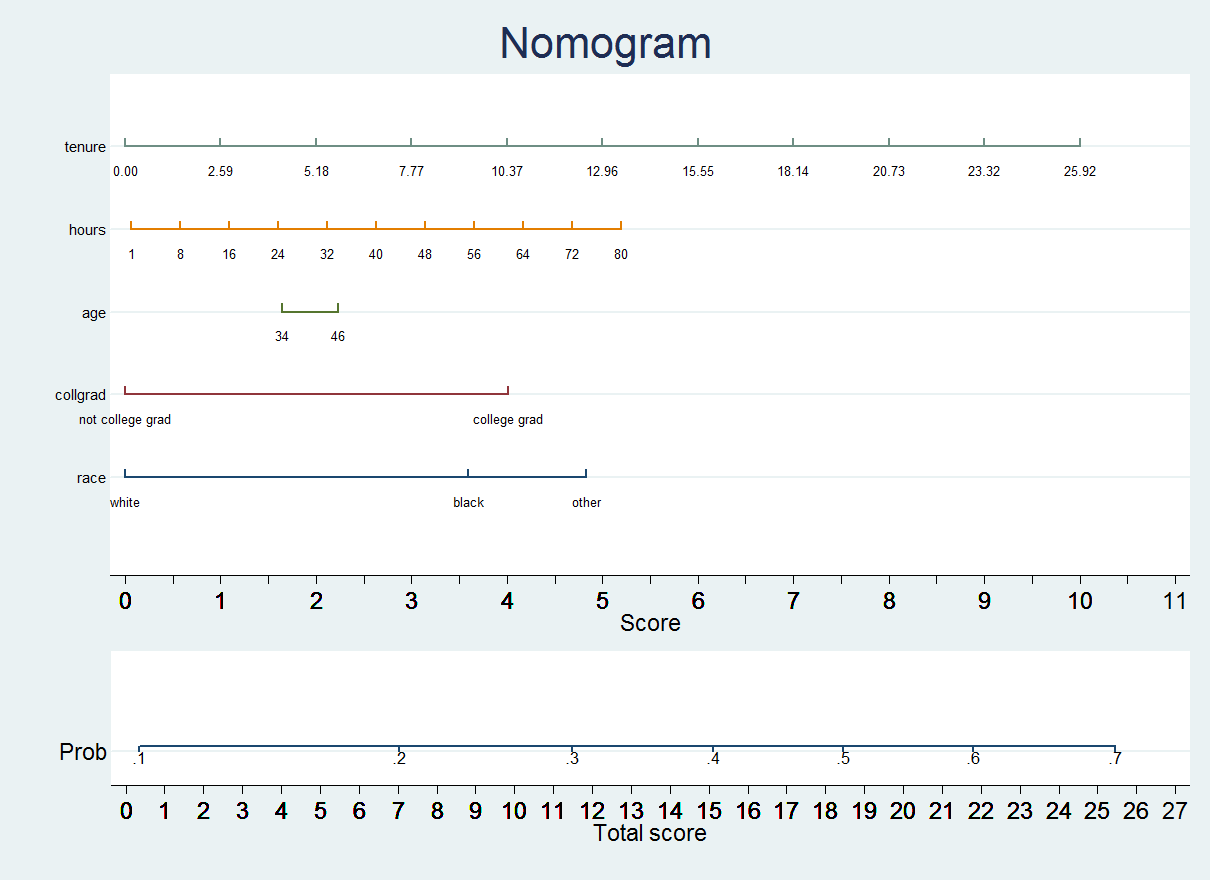
Disclaimer: I am not associated to StataCorp in any way. The purpose of this webpage is only to describe some useful programs and techniques for the Stata platform. > Suggested citation for nomolog and nomocox If you find these programs and/or the information included in this webpage useful for your research, please consider including the following citation: Zlotnik A, Abraira V. A general-purpose nomogram generator for predictive logistic regression models. Stata Journal. 2015. Volume 15, Number 2. > Can I get a printer-friendly version of this webpage? > What is nomolog? nomolog is a user-written program for generating nomograms for binary logistic regression predictive models. Sometimes, these are called Kattan-style nomograms. > What is nomocox? nomocox is a variation of nomolog. It generates nomograms for predictive Cox regression models. > Which versions of Stata are supported? Stata 12, Stata 13 and Stata 14. Older versions are not supported. All editions are supported (Small Stata / IC / SE / MP). Some issues may arise with Small Stata, in models with a large number of variables. Neither nomolog or nomocox are stand-alone programs. Both require Stata. > Why a Stata implementation? Alexander Zlotnik (Technical University of Madrid & Ramón y Cajal University Hospital) and Dr. Víctor Abraira (IRICYS & Clinical Biostatistics Unit, Ramón y Cajal University Hospital). > Are these programs free to use? Yes. > How can I get help / report a bug / suggest a new feature? 1) Have a look at this webpage. 2) Have a look at the official documentation for these commands (install the programs and then execute help nomolog or help nomocox). 3) If this does not solve your question, contact me. > What are logistic and Cox regression nomograms useful for? Why would I want to use nomograms? Why should I use nomolog and nomocox? - Nomograms allow calculating output probabilities for predictive models with a visual approach. This is useful when presenting the results of your predictive models in a convenient way in a printed format. Nomograms are better than most alternative approaches, such as providing the full regression formula or a table with all regression coefficients. Another possibility is to provide an on-line calculator, but this requires some programming and usually also "hides" the underlying model, while with a nomogram, the process is fully transparent. - With nomograms, variable importance is clear at-a-glance. The longer the line corresponding to a given variable, the more important a variable is. Therefore, nomograms can also be used in descriptive or exploratory data analysis. > What do I need to know about Stata to use nomolog and nomocox? This tutorial is mostly self-explanatory, however you can review the following concepts: - How to use factor (categorical) variable syntax - How to use interaction variables [optional, only if you plan to use nomograms for models with interactions] > How to install the Stata Journal version of nomolog If you wish to use an older version of nomolog, which appeared in the stata Journal, you should use these commands: .net from http://www.stata-journal.com/software .net cd sj15-2 .net describe st0391 .net install st0391 > How to install the latest version of -nomolog- There is an updated version of nomolog with several modifications, which is slightly different from the Stata Journal version. 1) Open Stata 2) Make sure that you have an active Internet connection. If you are behind a proxy (f.ex. if you are connecting from your workplace or your research center), you should follow these instructions. 3) Execute .ssc install nomolog [Note: not available yet on the SSC repository. If you wish to use a pre-release version, please contact me and I'll send you the program.] > How to install the latest version of -nomocox- Follow the same steps 1) and 2) as with the nomolog and 3) Execute .ssc install nomocox [Note: not available yet on the SSC repository. Still in a beta stage. If you wish to use a pre-release version, please contact me and I'll send you the program.] > How do I add nomolog and/or nomocox to the menu? > How to uninstall nomocox and nomolog Using these commands: .ado uninstall nomolog .ado uninstall nomocox > What is a nomogram? Nomograms are graphical calculators. Perhaps one of the best formal definitions we have seen is this one: Nomograms are one of the simplest, easiest and cheapest methods of mechanical calculus. (...) precision is similar to that of a logarithmic ruler (...). Nomograms can be used for research purposes (...) sometimes leading to new scientific results. Source: "Nomography and its applications" G.S.Jovanovsky, Ed. Naúka, 1977, USSR. Nomograms are widely used in several engineering disciplines. The Mizuhashi-Volpert-Smith chart, used in Electrical Engineering, is an example of a nomogram. Many non-linear functions can be represented as nomograms. Such is also the case with logistic and Cox regressions. > What is a Kattan-style nomogram? Although several nomograms have been used in biomedical research, Kattan nomograms are perhaps the most popular ones. One of the researchers who made several high-profile publications with logistic and Cox regression nomograms is Michael Kattan, PhD. You can generate Kattan-style nomograms with nomolog and nomocox. You can find more details about the specific nomograms that Kattan developed here. You can see an example of a Kattan nomogram here. > How does a logistic regression nomogram look like? Example of a logistic regression nomogram:
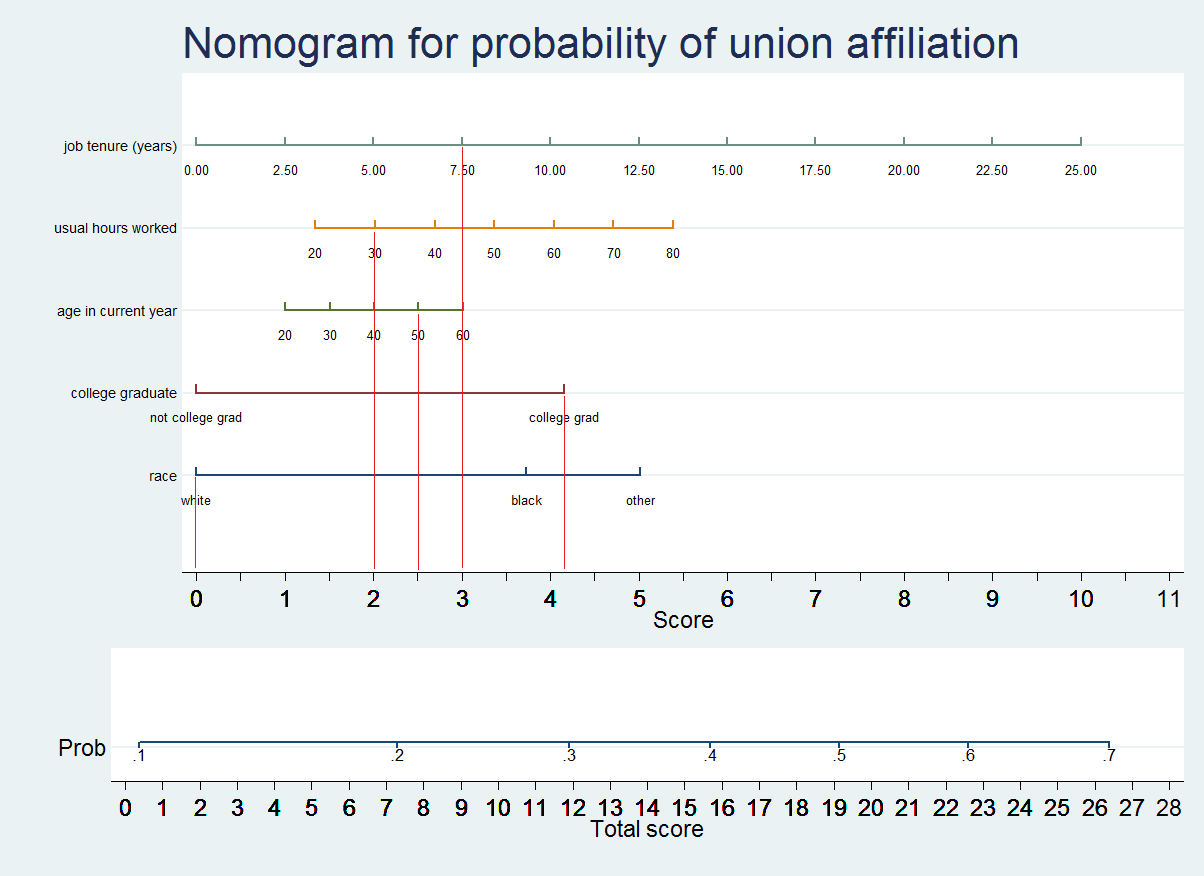
> How is a logistic regression nomogram used? Step 1) Establish scores for all variable values. Step 2) Obtain the Total score adding up all the scores obtained in the previous step. Step 3) Obtain the probability of event (Total Score -> Probability of event). Example: What is the probability of union affiliation for a worker who has a tenure of 7.5 years, works 30 hours per week, is 50 years old, is a college graduate and white? Step 1) Establish scores for all variable values. - Job tenure (years) = 7.50 => Score ≈ 3 - Usual hours worked = 30 => Score ≈ 2 - Age in current year = 50 => Score ≈ 2.5 - College graduate = yes / college grad => Score ≈ 4.2 - Race = white => Score ≈ 0
Step 2) Obtain the Total score adding up all the scores obtained in the previous step. Total score = 3 + 2 + 2.5 + 4.2 + 0 = 11.7 Step 3) Obtain the probability of event (Total Score -> Probability of event). Total score =11.7 is equivalent to a probability of approximately 0.28-0.29 > A (gentle) word of warning - A nomogram is a representation of a predictive model, not a validation tool. If the underlying model is not adequately calibrated, the output probabilities which you may obtain with a nomogram will be generally meaningless. You must ensure that the calibration (goodness-of-fit) of the model is adequate for your purposes on at least one representative validation dataset before generating a nomogram. Ideally, calibration should be tested on several representative validation datasets. One popular method for estimating calibration is the Hosmer-Lemeshow test. You may also use the visual inspection of the Homser-Lemeshow "deciles of risk" and/or calibration graphs and/or another methods. > Why are coefficients forced positive? This has to do with a hard-coded limitation in some graphics generation code within Stata core libraries, which cannot be modified. If too many labels are used, Stata yields an error and stops the execution. This limitation may or may not disappear in future Stata versions. > Basic usage of nomolog 1) Open Stata 2) Load a dataset Example: .net use datasetx [Note: datasetx does not actually exist; this command is used for illustrative purposes only] 3) Execute a logistic regression Example: .logistic outcome i.varcat1 b3.varcar2 varcont b1.varcat3##varcont2 [Note: interactions are supported. b1.varcat3##varcont2 is an interaction between a categorical variable and a continuous variable] 4) Execute nomolog without any options .nomolog This will generate the nomogram with the default options. Coefficients will be forced positive to facilitate calculations. Or, alternatively, execute nomolog with execution options which allow nomogram customization. You may use the command line or just use the dialog box. .db nomolog You should see the following dialog box:
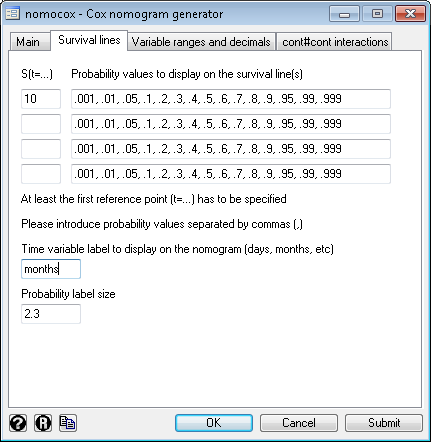
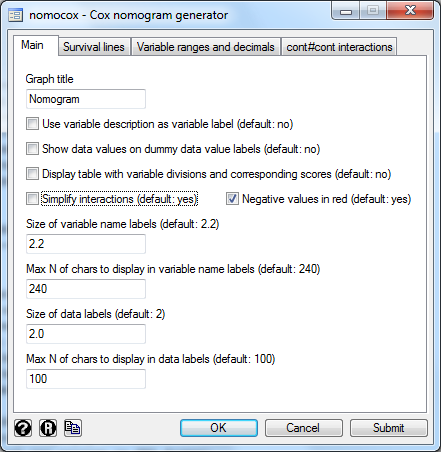
> Basic usage of nomocox Steps 1) and 2) are identical to those of nomolog. 3) Set a panel variable and execute a Cox regression Example: .stset timevar 4) Open the dialog box for nomocox .db nomocox You should see the following dialog box:
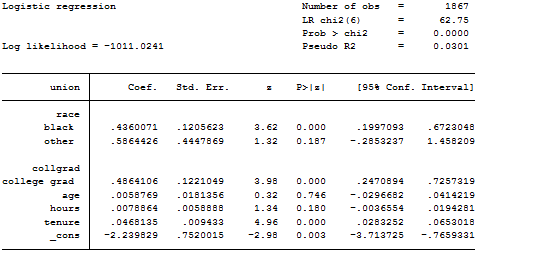
> A simple example with nomolog .sysuse nlsw88, clear .logit union i.race i.collgrad age hours tenure [Note: logit displays regression coefficients, instead of odd ratios] .nomolog > A simple example with nomocox .stset time, failure(censor)
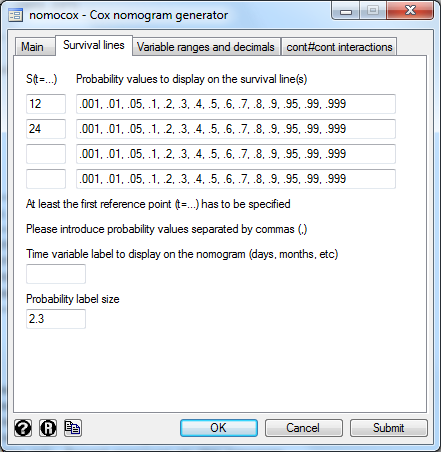
.nomocox, s1(12) s2(24)
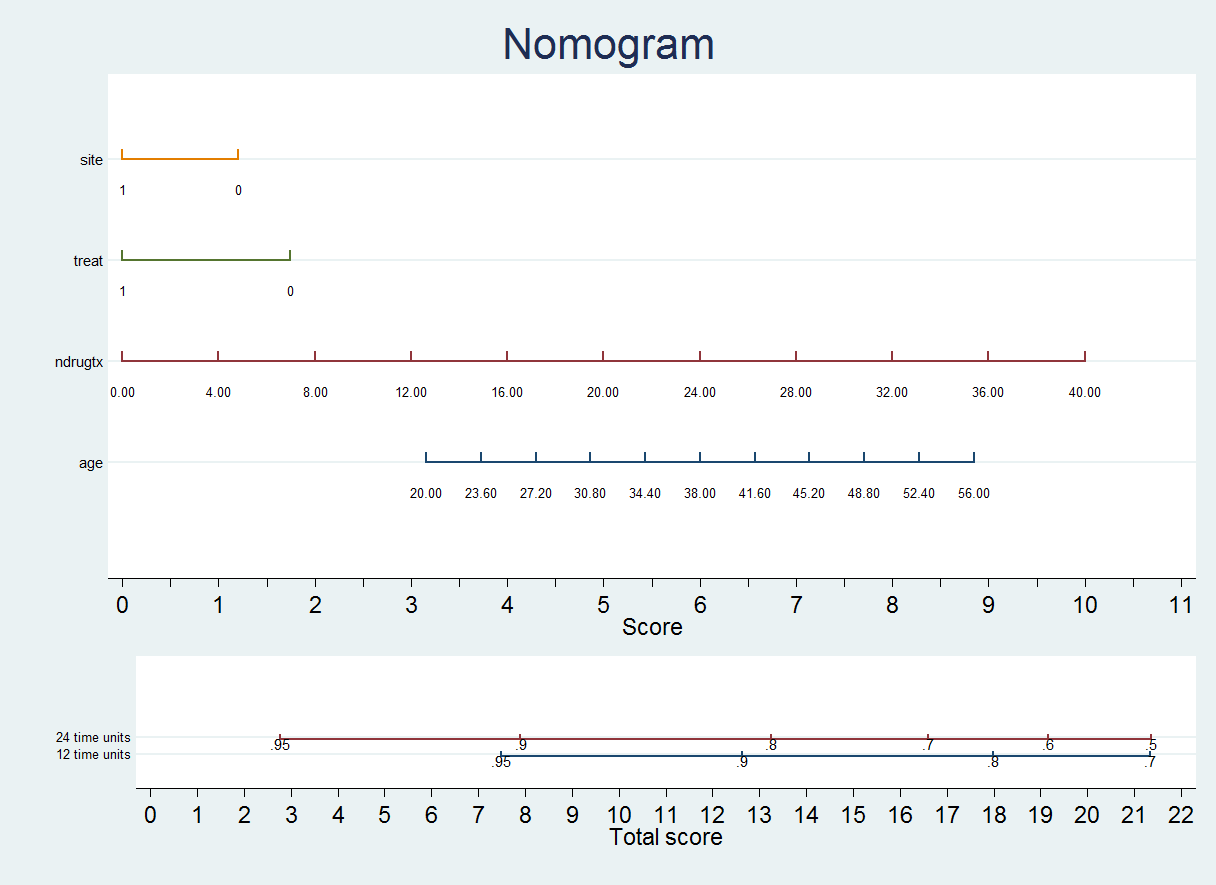
Step 1) Get the scores for all variables values Step 2) Add the scores = Total score Step 3) Calculated the probability of survival for a given number of time units given the Total score > Interactions in nomograms Both nomolog and nomocox support interactions. An interaction is a product of variables, i.e. interaction_variable = var_A * var_B 1) Categorical x Categorical 2) Categorical x Continuous 3) Continuous x Continuous This last case is slightly more complicated since cutpoints need to be specified on the nomogram in order to make it linear. In this particular case we are specifying cutpoints 10, 20 and 30 for var1. If we did a product of continuous variables, the resulting score calculation would not be linear > A simple example with nomocox .use http://www.ats.ucla.edu/stat/data/uis.dta, clear .stcox age ndrugtx i.treat##i.site (Notice that this is equivalent to .stcox age ndrugtx i.treat#i.site i.treat i.site)
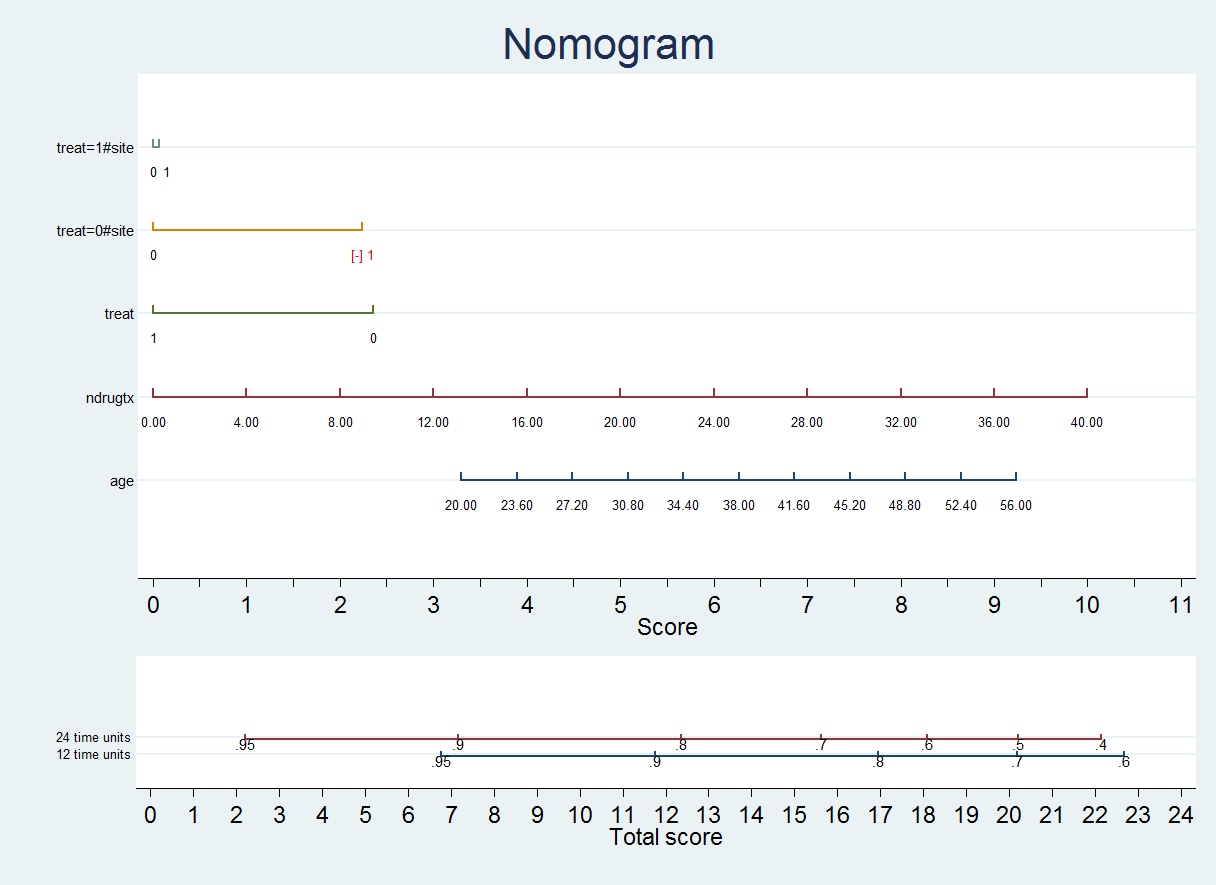
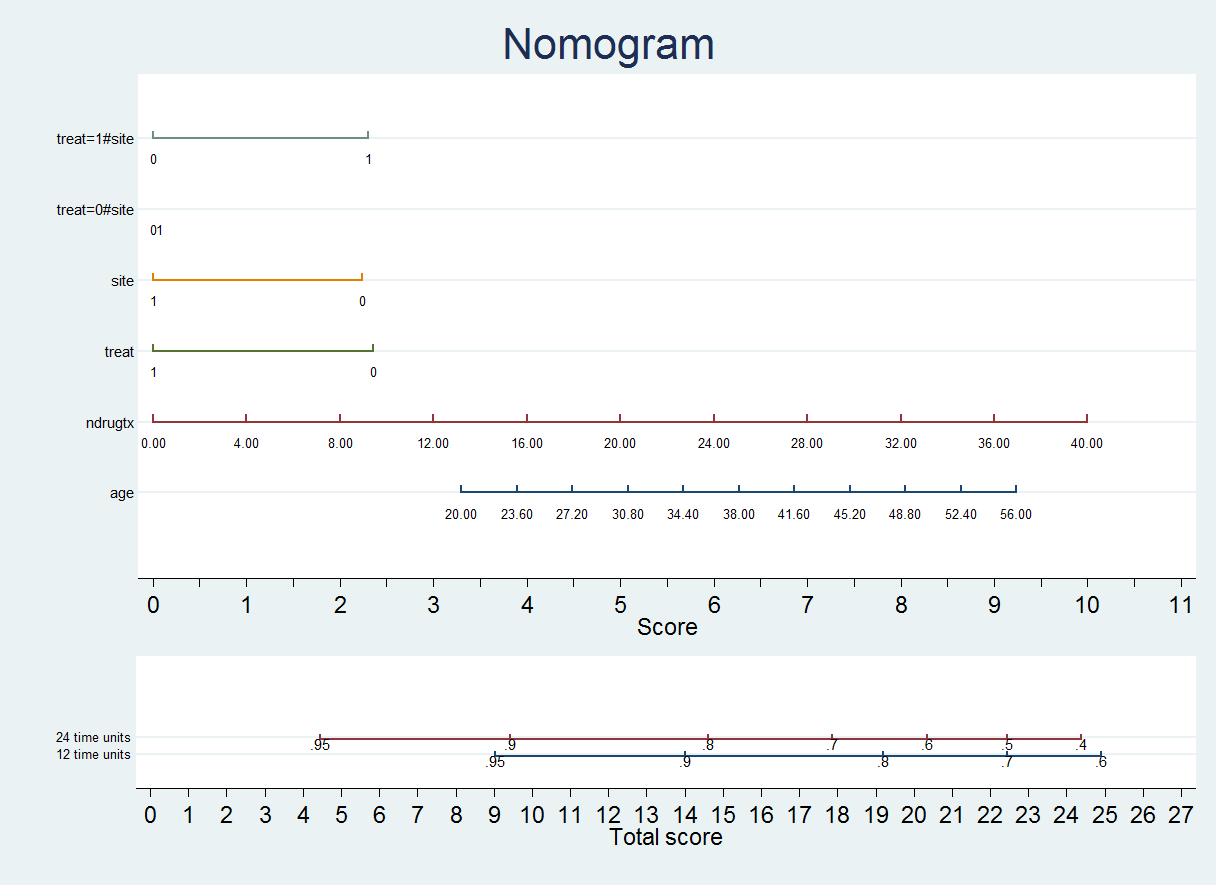
This generates the command: .nomocox, s1(12) s2(24) The resulting nomogram is: We see that the variable treat has two values: 0 and 1 If treat = 1, we choose the first line and obtain a score depending on the value of site: treat=1 and site=0 treat=1 and site=1 If treat = 0, we choose the second line and obtain a score depending on the value of site:  This line gives us the scores for: treat=0 and site=0 treat=0 and site=1 Notice that, in this particular case, there is a negative score if treat = 0 and site = 1 (marked with [-] and in red color) We would then calculate the score corresponding to treat:  By default both nomolog and nomocox simplify interactions. For example, in this case, we have removed the line corresponding to the effect of site combining it with the lines corresponding to the interaction of treat and site. However, in some cases, we may want to display all variables independently on the nomogram. .db nomocox
The resulting nomogram is the following:
Both nomograms (the previous one and this one) are equivalent. However, on the second one more variable has to be taken into account to make to obtain the outcome probability. > How to change variable label sizes 1) Open the dialog box. .db nomolog 2) Change the value in the corresponding box (for example 2.0):
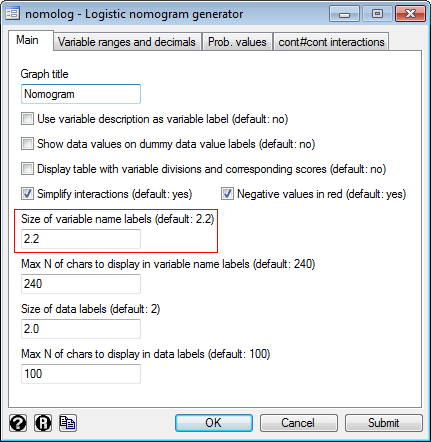
3) Press the "OK" button. 4) This will result in the following command being executed: .nomolog, varlblsize(2.0) [Note: 2.0 can be replaced with any decimal value] > How to display variable labels instead of variable names As you most likely know, Stata allows you to associate variable labels to variables. Some commands can make use of either. Example of label definition command: .label variable tenure "job tenure (years)" 1) Open the dialog box. .db nomolog 2) Mark the check box:
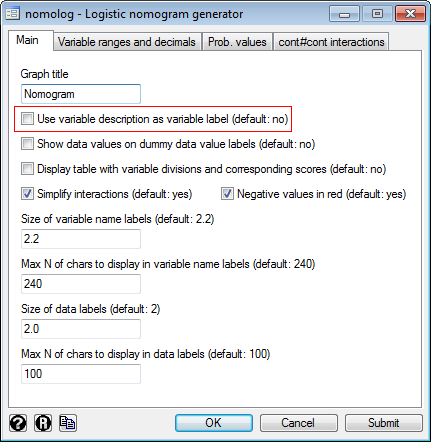
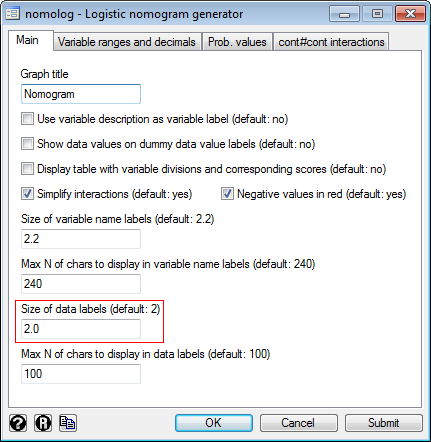
3) Press the "Submit" button. 4) This will result in the following command being executed: .nomolog, varlabdescr [Note: you may also use the command directly] > How to change the size of data labels (i.e. the numbers that appear above numeric variables and the names of the categories in categorical variables) .db nomolog 2) Change the value in the corresponding box (for example 1.8):
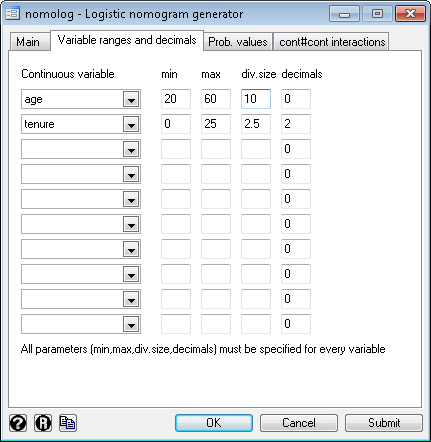
3) Press the "OK" button. 4) This will result in the following command being executed: .nomolog, datalblsize(1.8) [Note: you may also use the command directly] > How to change variable ranges In the example above, is it legitimate to extend the variable range from 20 to 60 years if your dataset actually ranges from 34 to 46 years? It depends. .db nomolog 2) Go to the "Variable ranges and decimals" tab. Introduce the variable(s), the new minimum(s), maximum(s) and division size(s):
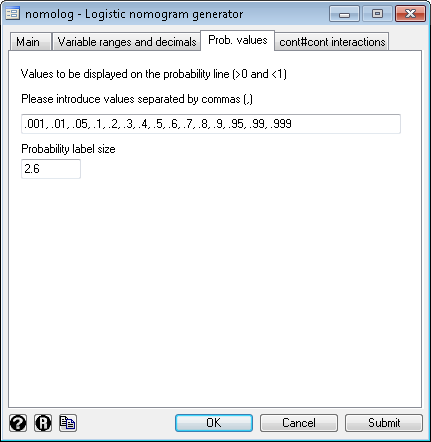
3) Press the "OK" button. 4) This will result in the following command being executed: .nomolog, vli1(age,20,60,10,0) vli2(tenure,0,25,5,2) [Note: you may also use the command directly] > How to change the probability axis range and/or probability label sizes 1) Open the dialog box. .db nomolog 2) Go to the "Prob. values" tab and insert the probability values you want to display:
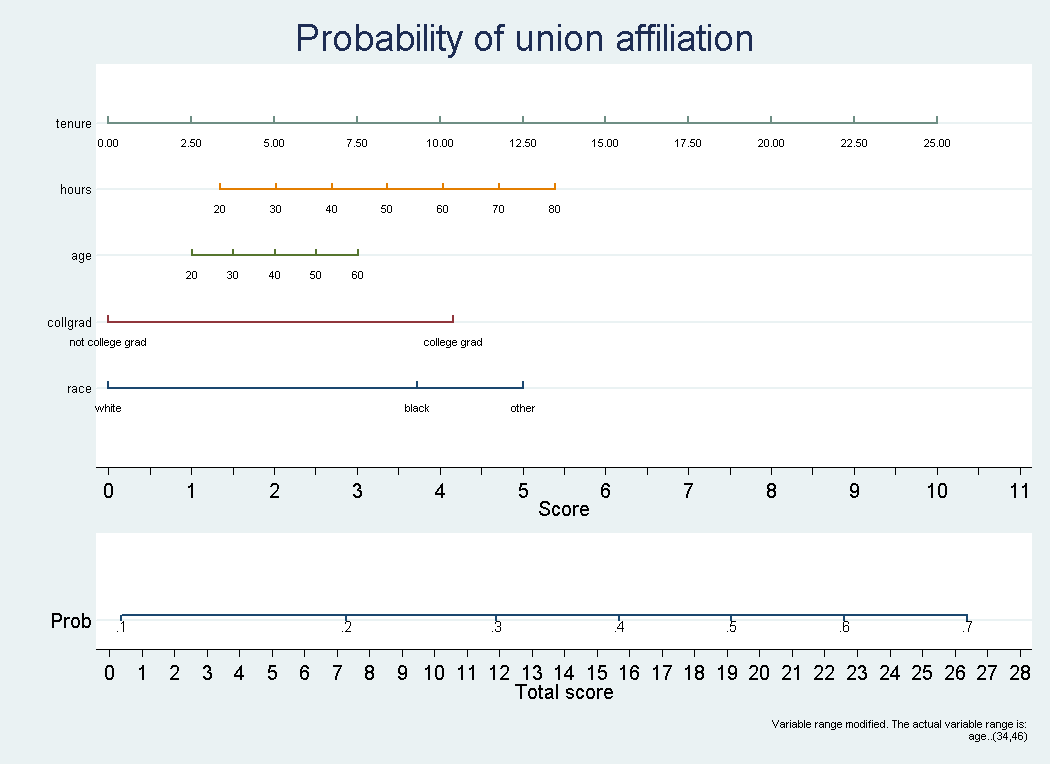
Notice that here you may also change the probability label size too. 4) This will result in the following command being executed: .nomolog, prvalues(.001, .01, .05, .1, .2, .3, .4, .5, .6, .7, .8, .9, .95, .99) [Note: you may also use the command directly] > Another example of the same nomogram using several execution options .sysuse nlsw88, clear .quietly logit union i.race i.collgrad age hours tenure [Note: "quietly" hides the output] .nomolog, vli1(hours,20,80,10,0) vli2(tenure,0,25,2.5,2) vli3(age,20,60,10,0) title("Probability of union affiliation") The resulting nomogram will look like this: Notice that, in this case, a warning has been added to the graph indicating that the range (min, max values to display) of variable age has been changed, i.e. the nomogram is actually showing an out-of-sample prediction (age values that were not in the derivation dataset). You may remove this warning using Stata's Graph Editor. > Is it possible to generate nomograms with interactions (products) between variables? Yes! > Is it possible to export the values of the divisions for all variables and the corresponding scores? Yes. Mark the option "Display table with variable divisions and corresponding scores" on the dialog box or use the option "divtable" if you are using the command line. > How to perform other modifications on the resulting graph(s) nomolog and nomocox generate standard Stata graphs, which can be edited with the Stata's Graph Editor. > Acknowledgments We would like to thank all Stata Corp technical support personnel we had the opportunity to work with, especially Statistician Joy Wang, and all the members of the Clinical Biostatistics Unit of the Ramon y Cajal University Hospital who have participated in the testing of this program. > References - Zlotnik A, Abraira V. A general-purpose nomogram generator for predictive logistic regression models. Stata Journal. 2015. Volume 15, Number 2. |